
| Version 25 (modified by , 16 years ago) ( diff ) |
|---|
Deriving an Initial Ontology from an Onyx Export
This is about deriving a first ontology from Onyx for trialing the import of an ontology and subsequent data into i2b2.
Nick's comments from meeting with Jason, Jeff and Dave
Working from variables.xml in MedicalHistoryInterviewQuestionnaire Top level of xml is the questionnaire - nothing pulled from export xml to populate this. Second level is taken from the stage name - all variables have a stage name attribute in the export xml. Third level is section name - all variables have a section name attribute. Fourth level is questionName - all variables have a questionName attribute. Fifth level is name of variable - defined in the <variable name=""> section of the export xml (or possibly constructed from variable name and category name, see below). Note that in some cases this will be the same as the fourth level. If this isn't a good idea, then the name will need to be extended by means of an additional string (maybe '.Question'?) <label> is derived from the variable's attribute "label" <type> is derived from the <variable valueType=""> declaration. * * * I've done the high BP questions (Do you.., When did you..., Have you received...) and then skipped all the other conditions as the question structure is essentially the same, albeit some with multiple categories for (e.g.) type of diabetes, treatment of diabetes, or with multiple question sets for multiple event conditions (MI, etc). * * * Discussion This is messy. Pulling the data only from each <variable></variable> element definition makes sense, but the 'category' variables (Y,N,PNA,DK,etc) would then have 'labels' of 'Y', 'N' and so on - put hundreds of those into i2b2 and you've got a very confusing ontology. Jeff's idea of using the <category> child elements of the original <variables> might therefore be a better idea, but it requires a more complex filter - where a variable has category child elements then the filter needs to construct additional ontology entries from those child elements (combining the variable label and the category label) and ignore the following variables (with the same root variable name) or possibly add detail from them, but where the variable doesn't have category child elements then it must behave differently. Thinking further, it would be better if the primary question <label> element related to the fourth level, not the fifth. Thus in the hierarchy there would be the primary question label, with 1 or more variables underneath it. NOTE a GOTCHA with questions that generate an integer value: the boolean variable is named e.g. part_hist_highbp_onset_cat but the integer value associated with it is just part_hist_highbp_onset. Definitively do not need: page attribute, required attribute, condition attribute, validation attribute. I don't think we need to bring over either the category 'code' attribute, or the 'missing' attribute, but maybe we do? Also don't think we need exclusiveChoiceCategoryVariable attribute, as the ontology just needs to provide all possible variables for all possible participants. Does the stage attribute of a variable ALWAYS match it's questionnaire attribute? Looks like it does. What is the 'script' attribute for? Does the ontology need to include the category variable 'code' attributes? Depends on the structure of the participant answer files. Looks like the codes aren't even mentioned in the answer files, so ignore them for now.
This is Nick's original example:
<briccs_questionnaire> <MedicalHistoryInterviewQuestionnaire> <MAIN> <part_hist_highbp> <label>Have you ever suffered from high blood pressure?</label> <part_hist_highbp> <type>text</type> <label></label> </part_hist_highbp> <part_hist_highbp.N> <label>No</label> <type>boolean</type> </part_hist_highbp.N> <part_hist_highbp.Y> <label>Yes</label> <type>boolean</type> </part_hist_highbp.Y> <part_hist_highbp.PNA> <label>Prefer not to answer</label> <type>boolean</type> </part_hist_highbp.PNA> <part_hist_highbp.DK> <label>Don't know</label> <type>boolean</type> </part_hist_highbp.DK> <part_hist_highbp.comment> <label>Comment</label> <type>text</type> </part_hist_highbp.comment> </part_hist_highbp> <part_hist_highbp_onset_cat> <label>When did you first suffer from high blood pressure?</label> <part_hist_highbp_onset_cat> <type>text</type> <label></label> </part_hist_highbp_onset_cat> <part_hist_highbp_onset_cat.YEAR> <label>Year</label> <type>boolean</type> </part_hist_highbp_onset_cat.YEAR> <part_hist_highbp_onset> <label></label> <type>integer</type> </part_hist_highbp_onset_cat.YEAR> <part_hist_highbp_onset_cat.PNA> <label>Prefer not to answer</label> <type>boolean</type> </part_hist_highbp_onset_cat.PNA> <part_hist_highbp_onset_cat.DK> <label>Don't know</label> <type>boolean</type> </part_hist_highbp_onset_cat.DK> <part_hist_highbp_onset_cat.comment> <label>Comment</label> <type>text</type> </part_hist_highbp_onset_cat.comment> </part_hist_highbp_onset_cat> <part_hist_highbp_treat> <label>Have you received treatment for your high blood pressure? </label> <part_hist_highbp_treat> <type>text</type> <label></label> </part_hist_highbp_treat> <part_hist_highbp_treat.N> <label>No</label> <type>boolean</type> </part_hist_highbp_treat.N> <part_hist_highbp_treat.Y> <label>Yes</label> <type>boolean</type> </part_hist_highbp_treat.Y> <part_hist_highbp_treat.PNA> <label>Prefer not to answer</label> <type>boolean</type> </part_hist_highbp_treat.PNA> <part_hist_highbp_treat.DK> <label>Don't know</label> <type>boolean</type> </part_hist_highbp_treat.DK> <part_hist_highbp_treat.comment> <label>Comment</label> <type>text</type> </part_hist_highbp_treat.comment> </part_hist_highbp_treat> </MAIN> </MedicalHistoryInterviewQuestionnaire> </briccs_questionnaire>
Jeff's Revision of the above into a no-attributes style xml:
<?xml version="1.0" encoding="UTF-8"?>
<source xmlns="http://briccs.org.uk/xml/v1.0/oi" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" >
<name>briccs</name>
<stage>
<name>MedicalHistoryInterviewQuestionnaire</name>
<section>
<name>MAIN</name>
<question>
<name>part_hist_highbp</name>
<label>Have you ever suffered from high blood pressure?</label>
<variable>
<name>part_hist_highbp</name>
<label></label>
<type>text</type>
<variable>
<name>N</name>
<label>No</label>
<type>boolean</type>
</variable>
<variable>
<name>Y</name>
<label>Yes</label>
<type>boolean</type>
</variable>
<variable>
<name>PNA</name>
<label>Prefer not to answer</label>
<type>boolean</type>
</variable>
<variable>
<name>DK</name>
<label>Don't know</label>
<type>boolean</type>
</variable>
<variable>
<name>comment</name>
<label>Comment</label>
<type>text</type>
</variable>
</variable>
</question>
<question>
<name>part_hist_highbp_onset_cat</name>
<label>When did you first suffer from high blood pressure?</label>
<variable>
<name>part_hist_highbp_onset_cat</name>
<label></label>
<type>text</type>
<variable>
<name>YEAR</name>
<label>Year</label>
<type>boolean</type>
</variable>
<variable>
<name>PNA</name>
<label>Prefer not to answer</label>
<type>boolean</type>
</variable>
<variable>
<name>DK</name>
<label>Don't know</label>
<type>boolean</type>
</variable>
<variable>
<name>comment</name>
<label>Comment</label>
<type>text</type>
</variable>
</variable>
<variable>
<name>part_hist_highbp_onset</name>
<label></label>
<type>integer</type>
</variable>
</question>
</section>
</stage>
</source>
Jeff's comments after initial work on the above ideas:
Learned some obvious lessons that require revision of the approach...
Basically not all variables are the result of a question. And it comes in various guises...
- Even in a Questionnaire stage, there are some variables not attached to any question, eg: QuestionnaireRun.version and other sorts of metric-like data.
- Some stages are not questionnaires (and therefore contain no questions), eg: the sample stages.
- Some are not even stages: see the Participant file within the export. The Participant file contains participant data retrieved via the PMI plus "other" admin type data, eg: Admin.Participant.birthDate and Admin.Action.user.
Jason's 'bash' at a stylesheet
I've been working on a stylesheet to take the variables.xml onyx extract and make it into Jeff's suggested ontology schema format so here it is :-
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:fn="http://www.w3.org/2005/xpath-functions"> <xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes"/> <xsl:template match="*"> <xsl:apply-templates select="variables"/> </xsl:template> <xsl:template match="/variables"> <xsl:element name="source"> <xsl:element name="name">briccs</xsl:element> <!-- only interested in variable elements with a child of categories --> <xsl:apply-templates select="variable[categories]"/> </xsl:element> </xsl:template> <!-- only want one stage element and subsequent section etc so apply only when it's the first in the list rather than all of them --> <xsl:template match="variable[categories][position()=1]"> <xsl:element name="stage"> <xsl:element name="name"> <xsl:value-of select="attributes/attribute[@name='stage']"/> </xsl:element> <xsl:element name="section"> <xsl:element name="name"> <xsl:value-of select="attributes/attribute[@name='section']"/> </xsl:element> <!-- to get the depth right we now need to go up the tree and get all the variables with categories and loop thru them --> <xsl:for-each select="//variable[categories]"> <xsl:element name="question"> <xsl:element name="name"> <xsl:value-of select="@name"/> </xsl:element> <xsl:element name="label"> <xsl:value-of select="attributes/attribute[@name='label']"/> </xsl:element> <!-- now get all the categories below where we are --> <xsl:apply-templates select="categories"/> </xsl:element> </xsl:for-each> </xsl:element> </xsl:element> </xsl:template> <xsl:template match="categories"> <xsl:element name="variable"> <xsl:element name="name"> <xsl:value-of select="../attributes/attribute[@name='questionName']"/> </xsl:element> <xsl:element name="type"> <xsl:value-of select="../@valueType"/> </xsl:element> <xsl:apply-templates/> </xsl:element> </xsl:template> </xsl:stylesheet>
Seems to work quite well but needs more effort around the variable/variable bit below question as I'm not entirely sure where we are sourceing this data from. I've attached the file as well for easier editing etc.
Feedback and intermediate results from Jeff
Jason, I'd hold off doing a lot of work on the style sheet approach at this stage. I see style sheets coming into their own in the next stage, where we have to process the intermediate xml into SQL insert commands. But I could be wrong.
The input is sourced from the export zip file which is attached to page Onyx Export and Purge. If you unzip this file you will find a directory structure for each "part" of the BRICCS questionnaire. Each directory has a variables.xml file plus a collection of data files for each participant exported from Onyx. It's the collection of variables.xml files which contain the metadata for each "part".
We obviously need to explore this in conjunction with trying to ascertain what the final input into i2b2 will be like. I expect a few iterations before we get anywhere near what is required. At the moment, I see producing an intermediate form of ontology from Onyx as a first step. This intermediate stage (probably an xml file for each Onyx part) will be used to produce SQL for the Ontology Cell and the ontology dimension table within the CRC Cell (the data mart). I believe the intermediate ontology might then be used to drive an intermediate format for the participant data files (the 0000001.xml type files within the export zip). We can then use whatever comes out of that process to produce CSV files for import into i2b2 (fact table and the patient table). The latter is managed from within the i2b2 workbench.
ONYX Export File | +-->variables.xml---(program?)--->intermediate ontology +---(XSLT)--> SQL inserts into Ontology Cell tables | | | | | +---(XSLT)--> SQL inserts into CRC ontology_dimension table | | | V +-->nnnnnnnnn.xml---(program?)--->intermediate data---------(XSLT)--> CSV file for import into CRC fact and patient tables
I'm agnostic as far as techniques are concerned (the bits in brackets). But I see XSLT as being admirably suited to doing the grunt work on producing SQL inserts and CSV files. The inserts into the Ontology cell for the demo data system were held in a file exceeding 250M in size, and I suspect even the first stab at Onyx will produce something relatively large. I've produced a first cut at processing a set of variables.xml files into an intermediate ontology and will attach a complete set corresponding to my example export zip file. I've struggled with aspects of trying to get a relatively systematized view from the collection of variables files. The idea being that one xsd file covers the whole structure, whatever variables file is chosen. There are some complex convolutions to derive variables and their grouping into different structures which I think is easier to explore programatically, at least for the moment.
The project I've started is currently in SVN within my sandbox area: onyx-to-i2b2. I'm uncertain about the structure of the project, and how it should eventually look, which is why it is sandboxed for the time being. When we have a better idea, code, examples, xslt, everything should be moved into another area of SVN and mavenized. There might need to be another project within the admin area of SVN which depicts scripts for exporting from onyx and readying for import into i2b2.
Comments On Structures So Far
Looking at the collection of variables.xml files from an Onyx export:
- Most parts of the Onyx export are stages, except for Participants.
- Most stages are Questionnaire based, but not all: BloodSamplesCollection, Consent and UrineSamplesCollection are the exceptions.
- Not all variables are question based. This is obviously true for non Questionnaires, but there are some variables even within stages that are not question based.
- Some variables have structured names "Admin.Participant.barcode" which are designed into Onyx. Easy enough to unpack into a structured ontology path.
- Some variables have structured names "famhist_death_sudden.brother4_death_sudden" which are allowed for but at the discretion of the questionnaire designer. The example is taken from the RiskFactorQuesionnaire. These look more of a problem to unpack in a meaningful way.
Please see attachments for a complete collection of intermediate ontology files produced from the Onyx export. They contain variations on the example structure due to struggling with the points listed in above comments. The schema file used to produce the intermediate ontology files is here: schema file
Here's a link to the attached graphical representation (PNG file) of the schema as at [2011-01-28] PNG file generated by XMLspy.
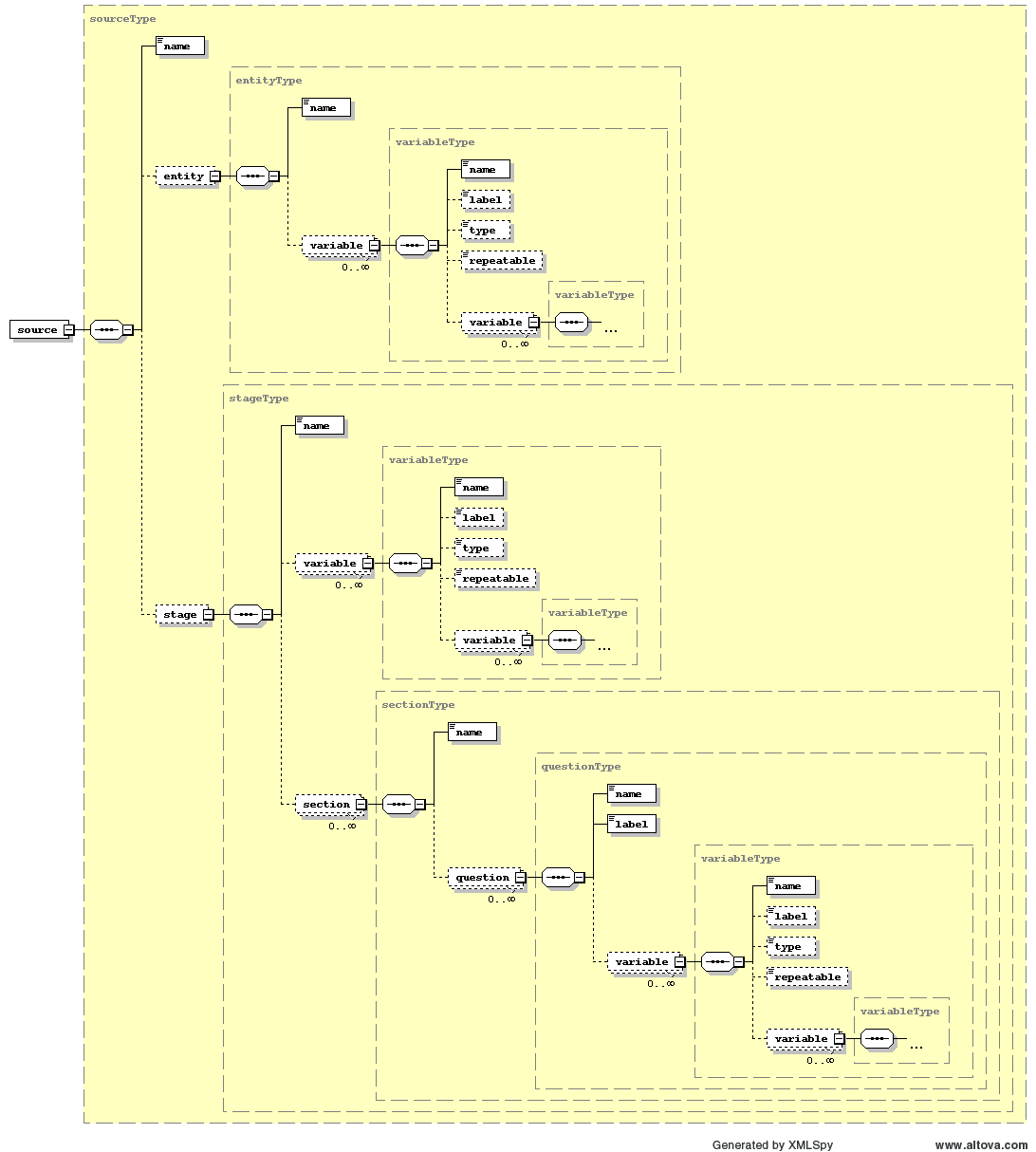{kind=link}
Some Principles Discovered
This may be stating the obvious, but perhaps worth actually putting into words.
We have variables which are question related and variables which are not question related. This is evident from the comments above. I suggest these are fairly good guiding principles:
- Variables (bottom leaf ones) which are not question related should be understandable by reading upwards from the bottom leaf until you encounter its top parent variable element. That one branch should contain all the information required to make sense of the variable. You should not have to read adjacent variables to gain critical information.
- Variables (bottom leaf ones) which are question related should be understandable by reading upwards from the bottom leaf until you encounter its top question element. That one branch should contain all the information required to make sense of the variable. You should not have to read adjacent variables or questions to gain critical information.
Of course, context information is held above these "top" parents (eg: which questionnaire is being focused upon), but this information applies to everything within one file in any case.
If we can manage to implement these principles, I suggest we have a reasonable looking ontology tree that would be derivable by machine. The alternative means some human intervention (case by case judgement). There may need to be an element of this, but hopefully minimal at this stage.
Some Omissions Discovered
With the above principles, I've been finding a few minor weaknesses (one may be irrelevant) and a fairly major omission. But nothing that cannot be corrected.
Weakness One
This is from the consent stage:
<variable name="mode" valueType="text" entityType="Participant">
<attributes>
<attribute name="stage" valueType="text">Consent</attribute>
</attributes>
<categories>
<category name="ELECTRONIC"/>
<category name="MANUAL"/>
</categories>
</variable>
Most categories are much more complicated than the above, particularly in a questionnaire stage, where they spawn a lower variable (like tobacco_any.N in the RiskFactorQuestionnaire where the N is described within the previous tobacco_any variable as a Category). But the above choices (ELECTRONIC and MANUAL) are a bit like stand alone enumerations. At present for categories this simple, the choices are being overlooked and are not collected, which represents a loss of information.
I suggest we collect this type of information by creating a lower level construct. I'm not sure what to call it, but I'm not concerned about the name provided it's not misleading. What about <enum>? We can always change our minds later.
Weakness Two
It is possible to have a question within a questionnaire stage where the question does not invoke an answer at all, under any circumstances. I've only encountered two of these. This one is from the ConclusionQuestionnaire:
<variable name="CONCLUSION" valueType="text" entityType="Participant">
<attributes>
<attribute name="stage" valueType="text">ConclusionQuestionnaire</attribute>
<attribute name="questionnaire" valueType="text">ConclusionQuestionnaire</attribute>
<attribute name="section" valueType="text">CHECKLIST</attribute>
<attribute name="page" valueType="text">1</attribute>
<attribute name="questionName" valueType="text">CONCLUSION</attribute>
<attribute name="boilerplate" valueType="boolean">true</attribute>
<attribute name="label" valueType="text" locale="en">This concludes the data collection process for this patient. Please ensure all notes are returned to the Medical Records Department.</attribute>
<attribute name="required" valueType="text">true</attribute>
</attributes>
</variable>
Note that this is basically a statement. There is a similar construct within the VerbalConsentQuestionnaire. They do not seem to require an answer, at least as far as I can see. I suggest we simply drop these. But it raises a good requirement: we need an exception report to highlight unusual cases when producing the intermediate ontologies.
Major Omission
At present some questions within the intermediate ontology are omitting useful information. Have a look at this from the RiskFactorQuestionnaire:
<variable name="family_table" valueType="boolean" entityType="Participant">
<attributes>
<attribute name="stage" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="questionnaire" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="section" valueType="text">FAMILY_HISTORY</attribute>
<attribute name="page" valueType="text">12</attribute>
<attribute name="questionName" valueType="text">family_table</attribute>
<attribute name="parentQuestion" valueType="boolean">true</attribute>
<attribute name="label" valueType="text" locale="en">Number of Family members.</attribute>
<attribute name="instructions" valueType="text" locale="en">Include all biological relatives: children, brothers and sisters, both living and deceased. If you have more than nine brothers/sisters/children, select '9'.</attribute>
<attribute name="required" valueType="text">true</attribute>
</attributes>
</variable>
There are a couple of things to note about this:
- questionName: family_table
- parentQuestion: true
- label: Number of Family members
If you examine the file there does not seem to be any other variables formally attached to the question "family_table", other than "family_table.comment". But in actual fact the following 16 or so variables describe the participant's family numerically: brothers, sisters and children. So really these variables are related. The above is a "parent" question whose human relevance is described by its label: "Number of Family members". Note that there is no formal way of attaching the detailed variables (eg: number of brothers) to the parent question unless we introduce the idea of nested questions; here for instance are the variable(s) for number of brothers:
<variable name="fam_brothers_cat" valueType="text" entityType="Participant">
<attributes>
<attribute name="stage" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="questionnaire" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="section" valueType="text">FAMILY_HISTORY</attribute>
<attribute name="page" valueType="text">12</attribute>
<attribute name="questionName" valueType="text">fam_brothers_cat</attribute>
<attribute name="label" valueType="text" locale="en">How many brothers do you have?</attribute>
<attribute name="required" valueType="text">true</attribute>
</attributes>
<categories>
<category name="OPEN_N_FAM"/>
<category name="PNA" missing="true" code="9998">
...
</category>
<category name="DK" missing="true" code="9999">
...
</category>
</categories>
</variable>
...
<variable name="fam_brothers" valueType="integer" entityType="Participant">
<attributes>
<attribute name="stage" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="questionnaire" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="section" valueType="text">FAMILY_HISTORY</attribute>
<attribute name="page" valueType="text">12</attribute>
<attribute name="questionName" valueType="text">fam_brothers_cat</attribute>
<attribute name="categoryName" valueType="text">OPEN_N_FAM</attribute>
<attribute name="openAnswerName" valueType="text">OPEN_N_FAM</attribute>
<attribute name="validation" valueType="text">[Number.Minimum[0], Number.Maximum[9]]</attribute>
<attribute name="condition" valueType="text">Questionnaire[RiskFactorQuestionnaire.family_table.OPEN_N_FAM]</attribute>
</attributes>
</variable>
It just so happens that in the above case the variables have reasonably meaningful labels or names.
But here is a more difficult one from the same questionnaire:
<variable name="famhist_cad" valueType="boolean" entityType="Participant">
<attributes>
<attribute name="stage" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="questionnaire" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="section" valueType="text">FAMILY_HISTORY</attribute>
<attribute name="page" valueType="text">13</attribute>
<attribute name="questionName" valueType="text">famhist_cad</attribute>
<attribute name="parentQuestion" valueType="boolean">true</attribute>
<attribute name="label" valueType="text" locale="en">Have any of your relatives suffered angina or other Coronary Artery Disease?</attribute>
<attribute name="required" valueType="text">true</attribute>
</attributes>
</variable>
Following this there are nearly one hundred related variables within a differently named question. Here is the first of these, which gives the answer with respect to father:
<variable name="famhist_cad.father_cad_occ" valueType="text" entityType="Participant">
<attributes>
<attribute name="stage" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="questionnaire" valueType="text">RiskFactorQuestionnaire</attribute>
<attribute name="section" valueType="text">FAMILY_HISTORY</attribute>
<attribute name="page" valueType="text">13</attribute>
<attribute name="questionName" valueType="text">father_cad_occ</attribute>
<attribute name="label" valueType="text" locale="en">Father</attribute>
<attribute name="required" valueType="text">true</attribute>
</attributes>
<categories>
<category name="Y" code="1">
<attributes>
<attribute name="label" valueType="text" locale="en">Yes</attribute>
</attributes>
</category>
<category name="N" code="0">
<attributes>
<attribute name="label" valueType="text" locale="en">No</attribute>
</attributes>
</category>
<category name="PNA" missing="true" code="9998">
<attributes>
<attribute name="label" valueType="text" locale="en">Prefer not to answer</attribute>
</attributes>
</category>
<category name="DK" missing="true" code="9999">
<attributes>
<attribute name="label" valueType="text" locale="en">Don't know</attribute>
</attributes>
</category>
</categories>
</variable>
The only connection that is obvious to the human reader is the structured variable name "famhist_cad.father_cad_occ", which is unfortunately entirely down to the questionnaire designer. It's an informal principle. Notice that if you do not connect the parent question to these lower variables formally defined within another question, then in this instance there is more of a loss of semantic information; viz, the absence of the label "Have any of your relatives suffered angina or other Coronary Artery Disease?"; the lower variables do not have such an expanatory label.
In my opinion that is a fairly major omission. As it stands, the information could only be retrieved by looking at an adjacent branch within the onotology.
Attachments (5)
-
onyxontology.xml
(2.6 KB
) - added by 16 years ago.
Nick's initial example of an intermediate form of xml that could be used to derive an ontology.
-
mapVariablesToOnyxOntology.xslt
(2.1 KB
) - added by 16 years ago.
maps the variables xml file to the onyx schema
-
onyx-i2b2-ontology.png
(20.5 KB
) - added by 16 years ago.
Graphical representation of the schema
-
onyx-to-ont-examples.zip
(51.9 KB
) - added by 16 years ago.
Intermediate ontology files. Third attempt.
-
onyx-i2b2-ontology.2.xsd
(2.4 KB
) - added by 16 years ago.
Schema used to produce the 3rd attempt at intermediate ontology files.
{kind=link}
Download all attachments as: .zip